A central challenge for every larger company is the consolidation and linking of master or transaction data. Data can be organised in a DWH such as SAP BW or unorganised in a data lake. It can also flow in as streaming data or come from other external sources. This leads to different and complex data orchestration scenarios.
Therefore, biX Consulting tested SAP Data Intelligence for its capabilities in this area in a proof of concept project for a large pharmaceutical company. It was investigated whether the tool is suitable for connecting different sources and targets, as well as reading and writing data and transforming it on the fly. Scenarios were designed for the PoC, which, in addition to setting up SAP DI and error handling, dealt with various cases focusing on transformation and orchestration.
SAP Data Intelligence is a system for coordinating and processing data. The data can be structured, unstructured or streaming data. Important components are profiling, data catalogue and governance, as well as machine learning. SAP DI is container-based and is accessed via a web application. On the one hand, this allows scaling and parallelisation of work processes, and on the other hand, it allows the desired work environment to be created container by container in terms of resources and software used. Work processes are put together in pipelines or graphs, which consist of individual operators. Operators can have inputs and outputs that form graphs through their connections. A large number of ready-made operators that fulfil special functions such as reading from SAP BW are already integrated. These operators are supplemented by the possibility to create custom operators. These can be used to implement your own JavaScript or Python code, for example.
For the PoC, SAP DI was set up as a separate on-premise installation that includes SAP DI Diagnostics and SAP Vora. Tenants, users and connections were created according to the test scenarios. The created connections to different systems could thus be used directly in the following scenarios. The test scenarios that are to examine transformation and orchestration will be briefly presented here.
Open API in Vora Table

In the first transformation scenario, data was loaded from a website and stored in a VORA file. The Open API Client is used to connect to the website. The query that is sent to the client and the subsequent transformation are created with a Python operator that contains its own coding. The transformation makes the data Vora-compatible. Wiretap operators, which are inserted between the operators, allow debugging and checking the intermediate results. They are removed for production use. The graph terminator terminates the graph after a single run.
ABAP table COEP via SLT with split in Kafka and HANA table
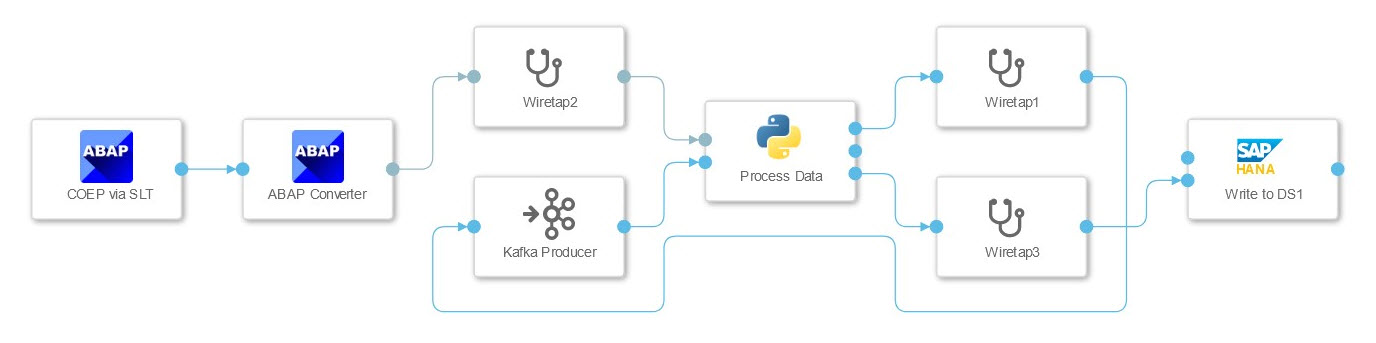
In this scenario, the connection to an SAP ECC system was tested, whose data is to be written to HANA and streamed using Kafka. The data from the ECC table was streamed using the SLT connector, which passes it as a JSON string to a Python operator. This has two tasks here. It passes the data to the HANA client operator and splits the data into packets that can be processed by the Kafka Producer. The graph is not terminated by the operator, but waits for further data. This must be taken into account when configuring the SLT connection, as using the same configuration multiple times can lead to deadlock.
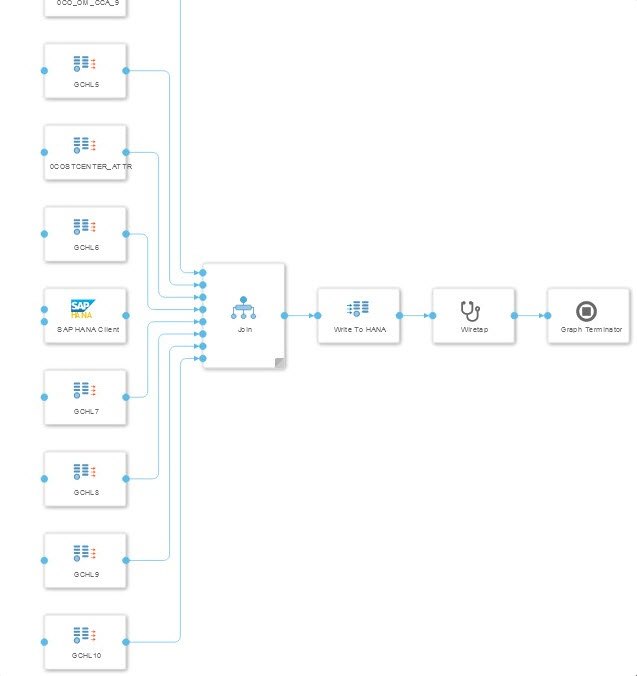
ECC data source joined with hierarchical text data from SQL server

In the third scenario, transaction data from an ECC was enriched with master data from an MS SQL server. The challenge for this scenario is to find suitable entries without having to load the entire data set. For the join, the data from the ECC was also stored in a database table. Since the information about the link between master and transaction data was in another ECC data source, a second graph was created. The first graph pulls the data from the ECC, the second graph creates the join between the two tables from the ECC and the six tables from the SQL server.
SAP BW extraction into two different HANA databases

Extracting data from SAP BW and writing it to two different HANA databases was investigated in this scenario. The extraction is carried out using a prefabricated operator that writes data to the Vora. Its result can be read by a Python operator that transforms the data and passes it to two separate HANA clients. The final Python operator waits for success messages from both HANA clients before terminating the graph by sending a message to the terminator operator.
Reading Kafka messages, transforming them and writing them to S3 files

Here we tested reading data packets from Kafka and saving them as S3 files. The incoming packets are transformed into csv format using a Python operator. This allows connected Spark or Vora systems to be connected with high performance. For testing purposes, information from the header such as timestamp and sequence of the data packets was also read out. The header of the output file can also be adapted to include information such as column names.
Conclusion
Even if some aspects are not yet fully developed at the time of project implementation, SAP DI can be recommended for data orchestration in the company. Flexibility plays a central role here. Flexibility comes from a large number of prefabricated operators that already cover many different application scenarios, as well as from the possibility to create your own operators with custom code. Flexibility also arises from the fact that the system is based on containers, which allow scaling and parallelisation.
In particular, the good integration with existing SAP solutions clearly sets the tool apart from other providers, without neglecting the integration of 3rd party solutions. This, coupled with consistent cloud use and integration, shows that the tool is a step in the right direction.
Contact Person


")



