Eine zentrale Herausforderung für jedes größere Unternehmen ist die Zusammenführung und Verknüpfung von Stamm- oder Bewegungsdaten. Daten können geordnet in einem DWH wie dem SAP BW oder ungeordnet in einem Data Lake liegen. Sie können auch als Streaming Daten einfließen oder aus anderen externen Quellen stammen. Das führt zu unterschiedlichen und komplexen Daten-Orchestrierungsszenarien.
Daher hat biX Consulting für ein großes Pharmaunternehmen in einem Proof of Concept Projekt SAP Data Intelligence auf seine Fähigkeiten in diesem Bereich getestet. Es wurde dabei untersucht, ob das Tool für die Anbindung von unterschiedlichen Quellen und Zielen geeignet ist, sowie Daten zu lesen und zu schreiben und dabei on the fly zu transformieren. Für den PoC wurden Szenarien entworfen, welche neben der Einrichtung von SAP DI und Error Handling verschiedene Fälle mit Schwerpunkt auf Transformation und Orchestrierung behandelten.
SAP Data Intelligence ist ein System für die Koordinierung und Verarbeitung von Daten. Die Daten können strukturiert, unstrukturiert oder auch Streaming Daten sein. Wichtige Bestandteile sind Profilierung, Data-Catalog und Governance, sowie Machine Learning. Ausgeführt wird SAP DI containerbasiert, der Zugriff geschieht über eine Webapplikation. Das erlaubt einerseits eine Skalierung und Parallelisierung von Arbeitsprozessen, andererseits containerweise die gewünschte Arbeitsumgebung in Hinsicht auf Ressourcen und verwendete Software zu erstellen. Arbeitsprozesse werden in Pipelines bzw. Graphen zusammengestellt, die aus einzelnen Operatoren bestehen. Operatoren können Eingänge und Ausgänge besitzen, die durch ihre Verbindungen Graphen bilden. Eine große Zahl vorgefertigter Operatoren, die spezielle Funktionen wie das Lesen aus dem SAP BW erfüllen, ist bereits integriert. Ergänzt werden diese Operatoren durch die Möglichkeit Custom-Operatoren zu erstellen. In diesen kann z.B. eigener JavaScript oder Python Code implementiert werden.
Für den PoC wurde SAP DI als eigene onPremise Installation eingerichtet, die SAP DI Diagnostics und SAP Vora beinhält. Den Testszenarien entsprechend wurden Tenants, User und Verbindungen angelegt. Die erstellten Verbindungen zu verschiedenen Systemen konnten so in den folgenden Szenarien direkt verwendet werden. Die Testszenarien, die Transformation und Orchestrierung untersuchten sollen, werden hier kurz vorgestellt werden.
Open API in Vora Table

Im ersten Transformationsszenario wurden Daten von einer Website geladen und in einem VORA File abgelegt. Für die Verbindung zur Website wird der Open API Client genutzt. Die Query, die an diesen gesendet wird, sowie die anschließende Transformation werden mit einem Python Operator erstellt, der jeweils eigenes Coding beinhaltet. Die Transformation macht die Daten Vora-kompatibel. Wiretap-Operatoren, die zwischen die Operatoren geschaltet werden erlauben Debugging und die Zwischenergebnisse zu prüfen. Für die Produktivsetzung werden diese entfernt. Der Graph Terminator beendet den Graphen nach einmaligem Durchlauf.
ABAP Tabelle COEP via SLT mit Split in Kafka und HANA Tabelle
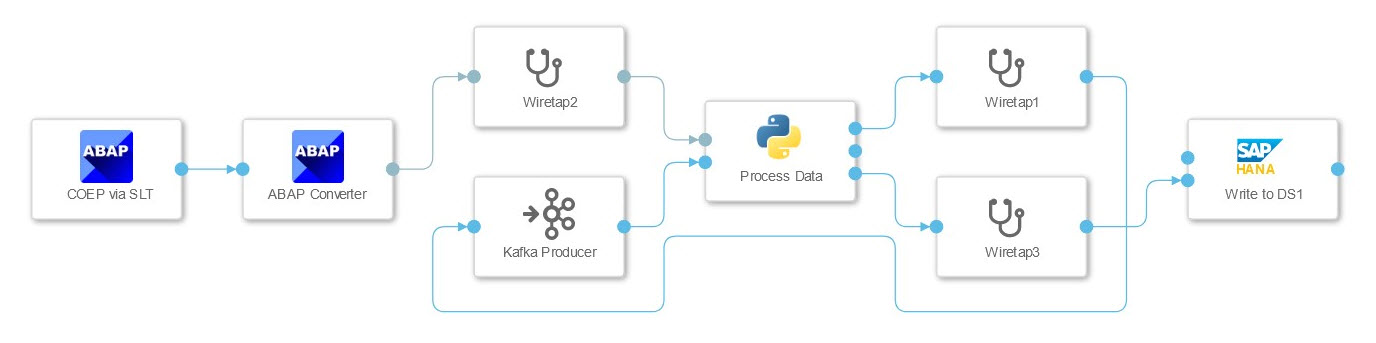
In diesem Szenario wurde die Verbindung zu einem SAP ECC System getestet, dessen Daten in die HANA geschrieben und mittels Kafka gestreamt werden sollen. Die Daten aus dem ECC Table wurden mittels SLT Connector gestreamt, der diese als JSON String an einen Python Operator übergibt. Dieser hat hier zwei Aufgaben. Er leitet die Daten an den HANA Client Operator und teilt die Daten in Pakete, die vom Kafka Producer verarbeitet werden können. Der Graph wird nicht per Operator beendet, sondern wartet auf weitere Daten. Das muss bei der Konfiguration der SLT Verbindung berücksichtigt werden, da die mehrfache Nutzung der gleichen Konfiguration zum Deadlock führen kann.
ECC Dataquelle gejoint mit hierarchischen Textdaten aus SQL-Server

Im dritten Szenario wurden Bewegungsdaten aus einem ECC mit Stammdaten aus einem MS SQL-Server angereichert. Die Herausforderung für dieses Szenario ist es passende Einträge zu finden, ohne den gesamten Datensatz laden zu müssen. Für den Join wurden die Daten aus dem ECC ebenfalls in einer Datenbanktabelle gespeichert. Da die Information über die Verbindung zwischen Stamm- und Bewegungsdaten in einer weiteren ECC-Datenquelle lag wurde ein zweiter Graph erstellt. Der erste Graph zieht die Daten aus dem ECC, der zweite Graph erstellt den Join zwischen den beiden Tabellen aus dem ECC und den sechs Tabellen aus dem SQL-Server.
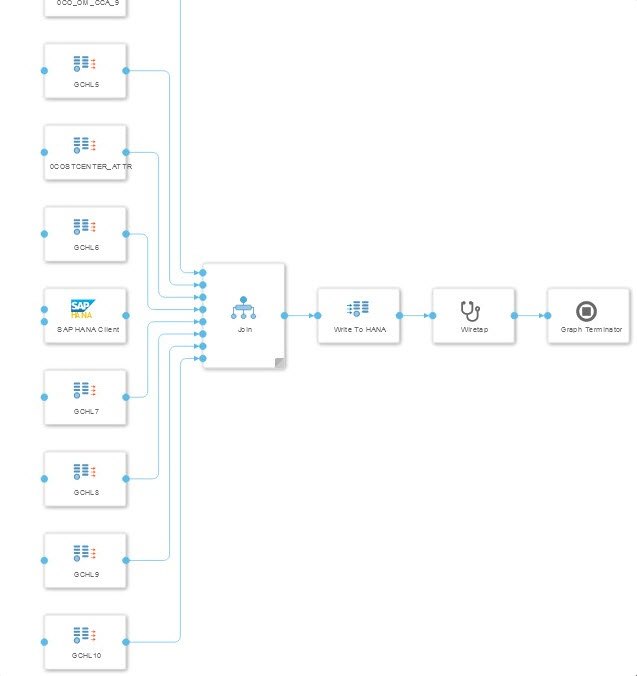
SAP BW Extraktion in zwei verschiedene HANA Datenbanken

Die Extraktion von Daten aus dem SAP BW und das Schreiben in zwei unterschiedliche HANA Datenbanken wurde in diesem Szenario untersucht. Die Extraktion erfolgt mittels eines vorgefertigten Operators, der Daten in die Vora schreibt. Dessen Ergebnis kann von einem Python-Operator ausgelesen werden, der die Daten transformiert und an zwei separate HANA Clients übergibt. Der letzte Python Operator wartet auf die Erfolgsmeldungen beider HANA Clients bevor er durch eine Nachricht an den Terminator-Operator den Graphen beendet.
Kafka Nachrichten lesen, transformieren und in S3 Dateien schreiben

Hier wurde das Lesen von Datenpaketen aus Kafka und die Speicherung als S3 Datei getestet. Die ankommenden Pakete werden mittels Python-Operator in das csv-Format transformiert. Das erlaubt angebundene Spark oder Vora Systeme performant anzuschließen. Zu Testzwecken wurden Informationen aus dem Header wie Zeitstempel und Reihenfolge der Datenpakete mit herausgelesen. Der Header der ausgegebenen Datei kann ebenfalls angepasst werden um Informationen wie bspw. Spaltennamen mitzugeben.
Fazit
Auch wenn einige Aspekte noch nicht völlig ausgereift sind zum Zeitpunkt der Projektdurchführung, kann SAP DI für die Daten-Orchestrierung im Unternehmen empfohlen werden. Flexibilität spielt hierbei eine zentrale Rolle. Flexibilität entsteht durch eine große Zahl vorgefertigter Operatoren, die viele verschiedene Anwendungsszenarien bereits abdecken, als auch durch die Möglichkeit eigene Operatoren mit Customcode zu erstellen. Flexibilität entsteht auch durch die Basierung des Systems auf Containern, welche Skalierung und Parallelisierung erlauben.
Insbesondere die gute Integration mit bestehenden SAP-Lösungen hebt das Tool deutlich von anderen Anbietern ab, ohne die Integration von 3rd Party Lösungen zu vernachlässigen. Dies gepaart mit einer konsequenten Cloud-Nutzung und -Integration zeigt, dass das Tool ein Schritt in die richtige Richtung ist.
Ansprechpartner


")



