In March, the Q2 2021 release added several new features to SAC. Among them is a way to make data modelling more flexible and effective. A new model is made available to the modeller, which can now also be used to create key figure models.
Until now, it was not possible to map key figure models in the SAP Analytics Cloud. If the data source in a system was available as a key figure model, a mapping from a key figure model to an account model had to be carried out with additional effort so that the data could be evaluated/planned. Now this is finally history. SAC enables both in one model.
This new data model is referred to in this article as a hybrid model. Hybrid because both a ratio model and/or an account model can be created from a hybrid model. This model will, it seems, replace the old data model (here referred to as the Classic Account Model (see Figure 1)) in the future and thus move into focus for new developments and functions.
The new data model on the SAC can be used by...
- Start with a blank model and then click on New Model in the selection in Figure 1 below or
- For an existing model (Classic Account Model), select Migrate to New Model Type under Edit (see Figure 2).
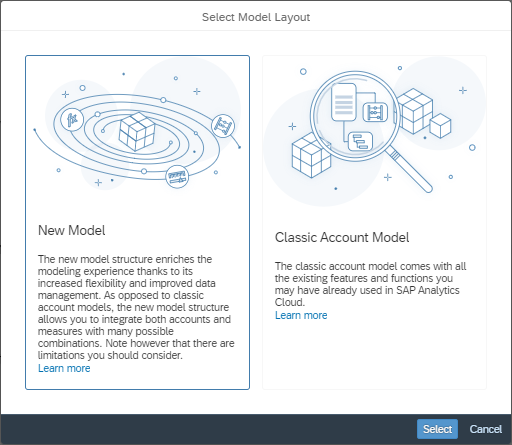
Figure 1: Create New Model -> Blank Model -> New Model
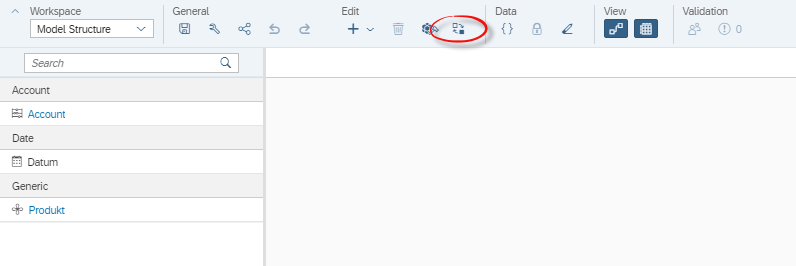
Figure 2: Workspace Model Structure -> Edit -> Migrate (marked red)
This article will give an insight into the hybrid model, how to handle it and what to consider when migrating existing models (Classic Account Models).
First impressions
The hybrid model finally makes it possible to create key figure models and thus build completely new scenarios. It is becoming more important to think about how one's models should be modelled on the SAC, because it can reduce and improve data volumes. Furthermore, it also makes it possible to connect existing data models from other systems that were not connectable until now (except with additional mapping to an account model) to the SAC.
Further differences
New number types
Another innovation that comes with the hybrid model are new number types, e.g. integers. In the future, it will finally be possible to plan entire bicycles without having to set up the workaround with decimal places, with the risk that calculations will be rounded up in the background.
No automatic creation of master data
With the Classic Account Model, new master data is automatically created when loading. This is not (yet) possible with the hybrid model. When loading, it must therefore be ensured that all master data is maintained beforehand.
Currency conversion
The possibilities for currency conversion during planning have also been extended. Now you can, for example, enter values in transaction currency and have them translated directly into company code and group currency during entry before transferring the data! This facilitates consistent entry.
Calculated and restricted key figures
In addition, calculated and restricted key figures can now be created without having to create them via Account.
Create data model from dataset only works for account models
These new features encourage new developments to be created in the hybrid model. Unfortunately, the hybrid model cannot be generated from a dataset, it must always be created. It makes no difference whether the data source is an account model or a key figure model. SAP always generates an account model that can be manually migrated into a hybrid model (see next chapter).
Migration
The most striking thing about a migration is that the familiar Data Wrangling Editor is no longer needed. This means that SAC does not yet have any functions that allow adjustments to be made when the models are transferred. A mapping function would have been in good hands there, in order to fill several from one key figure (depending on the account dimension). After activating Migrate to New Model Type, the old model is deleted and SAC creates a hybrid model. If I am not satisfied with the migration, there is no Undo! So it is very important that some steps are prepared beforehand
A model that is in use should never be migrated. This is also not possible because stories cannot be migrated. It is better to create a duplicate of the model to be migrated. This duplicate has no connections to Stories and can therefore be migrated. The stories would either have to be rebuilt manually or you try it by duplicating the stories as well, and deposit/exchange the hybrid model as a new data source.
It is also important to ensure that the currency conversion is switched off, otherwise no migration can take place. After the migration, the currency conversion can be switched on again. Import jobs are also not migrated. Thus, all migrated models should be checked for this.
Another important point is that when migrating existing account models, the unit properties are omitted. On the old Classic Account Model, the unit & currency can be set via the dimension Account, as can be seen in Figure 3.

Figure 3: Classic Account Model: Dimension Account
A story on this model also shows the units & currencies from the Account dimension accordingly with the symbols (see Figure 4).
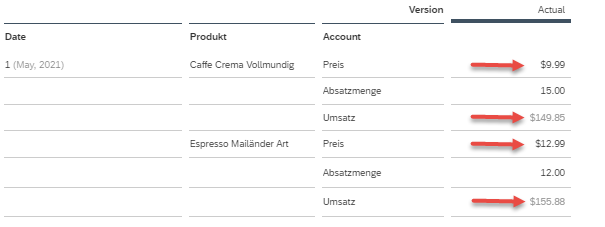
Figure 4: Story on a Classic Account Model
Figure 5 shows that the currency symbols are omitted after migration. This is because the hybrid model does not know any mixed key figures. The automatically generated ratio has a field where the unit & currency can also be set. However, one must decide whether this key figure contains units or amounts. In the example shown, the account model to be migrated contains units of quantity and currency. After migration, the ratios will all be interpreted as either income or amounts. However, it is also possible to create a unitless key figure. This setting can be seen in the figure below. Care must be taken when creating reports to ensure that the user interprets their ratios correctly.

Figure 5: Story on a hybrid model (after migration)
This is still the biggest problem with the hybrid model. To complete the migration, the key figures must be split into several key figures (amount, quantity) (see the following thought experiment).
Thought experiment
To enable a complete migration, additional manual effort is then required. One idea would be to duplicate the Classic Account Model to be migrated as many times as there are different units in the original model. Each of the duplicated Classic Account Models would then have to be trimmed down to one unit in the model, so that in our case there is one model with only units of measure and one model with only currencies. These could then be migrated individually. After the migration, the corresponding unit must be assigned to the automatically created key figure.
The two models could then be stored in a story and linked to each other. This function is called data blending. However, there are limitations to this. Further information on data blending (https://blogs.sap.com/2019/11/05/sap-analytics-cloud-blending-information-part-1/).
Alternatively, a DataAction could be used to copy the values of one model into a new key figure of the other.
This would allow the data to remain jointly evaluable.
Conclusion
The hybrid model already fulfils a long-awaited wish to be able to map key figure models. This enables flexibility in data modelling, as well as possible performance advantages. In addition, other data sources can now be connected to the SAC that could not be connected before due to their key figure model. Newly created data models will mostly be developed on the hybrid model because this offers more flexibility.
However, there is still room for improvement when migrating from a Classic Account Model to a Hybrid Model. Losing units is a challenge that does not encourage Classic Account models to migrate. It remains to be seen whether SAP will address this issue.
It is also exciting to see whether SAP will migrate the standard content or create new content.
More information can be found under the link (https://saphanajourney.com/sap-analytics-cloud/resources/sap-analytics-cloud-new-model/) or in the help in the SAC. The other findings are derived from try & error (as of 28.04.2021).
Contact Person


")



