In einem Composite-Provider kann man nun neue Merkmale oder Kennzahlen per eigenem SQL füllen!
Dies ist eine spannende Funktion, mit der man viele Anforderungen elegant lösen kann. Verwendet man dies bei Kennzahlen, kann es jedoch passieren, dass das Ergebnis nicht ganz den Erwartungen entspricht und sich sogar noch verändert, wenn man andere Kennzahlen mit in den Aufriss nimmt. Daher soll hier mit einem einfachen Beispiel das Verhalten analysiert und erklärt werden. Dann steht eine Verwendung dieser mächtigen Funktion ohne „böse“ Überraschung auch nichts mehr im Weg.
Der Blog ist wie folgt aufgebaut:
- Vorstellung der neuen Funktionalität
- Erklärung des kleinen Beispiels
- Überraschende Ergebnisse
- Vermeidung der „falschen“ Berechnung
Die neue Funktionalität
Wenn das BW/4 auf ausreichendem Patch-Level ist (HANA 2.0 SPS 04), sieht man folgende neue Option im Composite Provider:
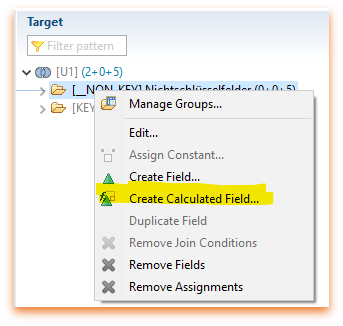
Um aus einem nummerischen Attribut eine Kennzahl zu erzeugen, reicht nun folgendes SQL:
snumc_to_int( „ATTRIBUTE_NUMC“ )
Damit ist der Composite-Provider noch einmal viel mächtiger geworden und vermeidet wohl häufig die Verwendung eines Calculation Views oder erspart das Anlegen und Füllen einer neuen Kennzahl / eines neuen Merkmals im aDSO. Insbesondere die Vermeidung des Calculation Views hilft, nicht noch eine weitere Technik einzuführen. Außerdem ist nicht immer der Zugriff direkt auf die HANA gewünscht.
Diese Funktion findet man in den SAP–Release Informationen (https://help.sap.com/viewer/b3701cd3826440618ef938d74dc93c51/2.0.6/de-DE/d8b12ec099e04e6aa77a312be687db63.html) und in diesem schönen Blog https://www.brandeis.de/en/blog/sql-expressions-in-bw-4hana-composite-provider-hcpr/ gut beschrieben.
Kleines Beispiel
Schauen wir uns das Verhalten an folgendem Beispiel einmal an. (Das Beispiel erhebt keinen Anspruch auf fachlichen Sinn, es sollen nur mit einfachen Zahlen und Rechnungen die Ergebnisse leicht nachvollziehbar sein ?. Ebenso gibt es evtl. für die Fragestellungen noch andere Lösungsansätze, aber diese sollen hier nicht betrachtet werden. Wir möchten nur die Funktion der SQL–Verarbeitung nachvollziehen!).
Wir haben ein aDSO, das wie folgt aufgebaut ist:
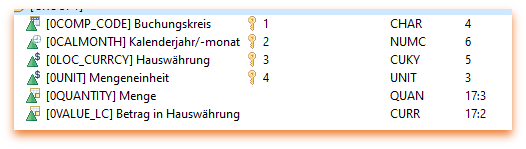
Nun wollen wir folgende Kennzahlen im Calculation View ergänzen:
Menge mit dem Monat gewichten, d.h. Menge im Januar * 1, Februar *2 etc.
Damit alle Schritte kontrolliert werden können, sind diese als einzelne Merkmale bzw. Kennzahlen angelegt. Dies wäre natürlich auch in einem Schritt möglich
In einem ersten Schritt holen wir aus 0CALMONTH den Monat.
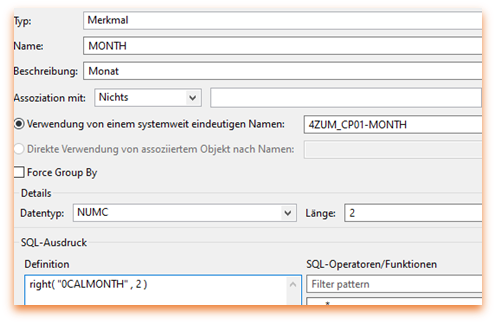
Danach wandeln wir den Monat in eine Kennzahl um.
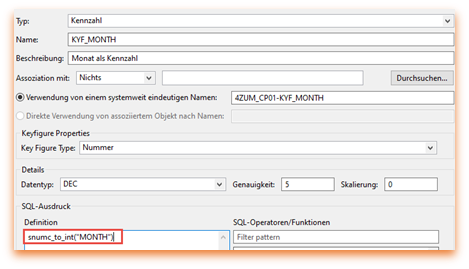
Zum Abschluss noch mit der Menge multiplizieren.
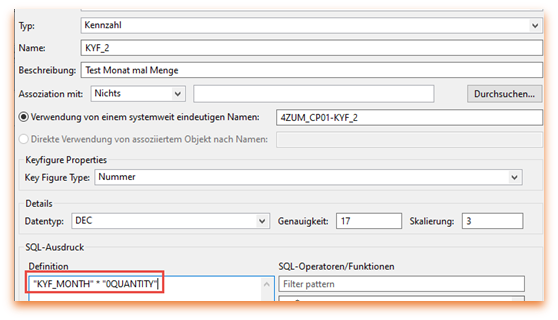
In einem weiteren Beispiel sollen die Einträge mit EUR als Währung gezählt werden, d.h. die Kennzahl soll immer 1 enthalten, wenn die Währung EUR enthält. Dies ist mit folgender SQL–Anweisung möglich:
CASE „0LOC_CURRCY“
WHEN ‚EUR‘ THEN 1
ELSE 0
END
Überraschende Ergebnisse
Sind alle Attributte aufgerissen, dann erfolgt die Berechnung, wie wir sie intuitiv erwarten:

Werden keine Attribute in der einfachen Query / Listcube angezeigt, bekommt man folgendes Ergebnis:
- die Zählung der Monate mit EUR liefert einen Monat zu wenig (vorletzte, erwartet 4, nun 3)
- die Summe der Monate als Kennzahl kommt zu einem anderen Ergebnis (letzte Spalte, erwartet 22, nun 21)

Noch verwirrender wird es, wenn man sich nur die Kennzahl zur Zählung der Monate mit EUR anschaut und die Währung anzeigt. Beides mal haben wir in den Zeilen die Währung, in der Spalte nur die eine Kennzahl, aber Achtung:
- Der Bericht auf dem Composite, der die Kennzahl filtert, liefert das erwartete Ergebnis von 4, in der Summe, allerdings nur 3!

- Speicher man das Workbook und frischt es wieder auf, so wird das Gesamtergebnis auf einmal wie erwartet mit 4 angezeigt
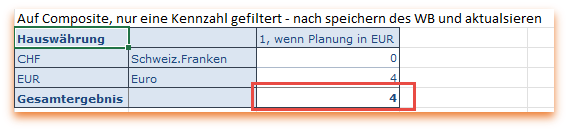
- Eine Query mit nur einer Kennzahl in den Spalten liefert aber nur 1.

Ursache für die „falschen“ Ergebnisse
Um die Performance zu optimieren, werden die Daten immer zuerst so weit wie möglich aggregiert und dann wird das SQL für die neuen Merkmale im Composite-Provider ausgeführt.
Werden also zwei Attribute in der Berechnung benötigt, dann werden die Daten auf diese Ebene aggregiert, die Berechnung durchgeführt und dann weiter aggregiert, wenn dies für die Anzeige nötig ist.
Die Berechnung aller verwendeten Kennzahlen wird auf derselben Ebene ausgeführt, d.h. wenn mehrere Berechnungen durchgeführt werden müssen, dann wird nur so weit aggregiert, dass alles gleichzeitig berechnet werden kann.
Dies führt dazu, dass die Berechnungen unterschiedlich ausfallen können, ja nachdem, welche Kennzahlen gleichzeitig angezeigt werden sollen. Sind alle Merkmale im Aufriss, dann erfolgt die Berechnung auf der untersten Ebene.
In unserem Fall werden der Monat und die Währung benötigt, um die Berechnung für alle Formeln wie erwartet durchzuführen. Wenn daher alle Kennzahlen vorkommen, aber keine Merkmale im Aufriss sind, wird zuerst auf diese Ebene verdichtet. Dass wir im Januar in zwei Buchungskreisen Zahlen in EUR haben, ist egal, da diese Zeile nur einmal vorkommt und damit nur einmal gezählt wird. Daher erhalten wir hier nur einen 3 statt der 4. Lässt man noch die Währung anzeigen, dann scheint noch eine weitere Logik bei den Einzelzeilen zu ziehen, die hier nun wieder zu einer 4 führt. Noch verwirrender wird es, wenn man diese Darstellung abspeichert und wieder aktualisiert. Dann ist auf einmal auch das Gesamtergebnis richtig.
Haben wir nur die Kennzahl zur Zählung der EUR–Zahlen in der Query angefordert, dann erfolgt hier eine Verdichtung bis auf die Währung, bevor das SQL ausgeführt wird. Daher erhalten wir die 1 für einmal Ausprägung EUR.
„Richtige“ Berechnung erzwingen
Zum Glück gibt es die Möglichkeit, die Query zu überzeugen, „korrekt“ zu rechnen.
Hierfür müssen zwei Einstellungen geändert werden. Zuerst legen wir eine Formel an, die die eigentliche Kennzahl übernimmt und für die wir die Ausnahmeaggregation definieren:
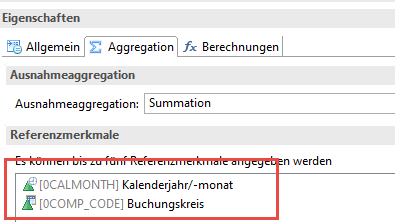
Als Referenzmerkmale sind alle Merkmale anzugeben, die wir bei der Berechnung berücksichtigen möchten. Da hier maximal 5 Merkmale erlaubt sind, ist dieses Vorgehen sicher nicht für jedes Modell geeignet. Aber häufig benötigen wir hier nicht alle Merkmale des Modells, sondern nur diejenigen, die sich unabhängig unterscheiden können, bzw. die bei der Zählung zu berücksichtigen sind. So reicht z.B. in vielen Modellen vermutlich die Belegnummer.
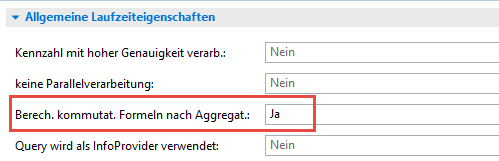
Allein mit dieser Ausnahmeaggregation erfolgt erstaunlicherweise immer noch keine korrekte Berechnung. Erst, wenn im Reiter Laufzeiteigenschaften der Query die Einstellung „Berech. Kommutat. Formel nach Aggregat.:“ auf Ja gestellt wird, kommt das „richtige“ Ergebnis heraus:

Ob man die Berechnung auf unterer Ebene erzwingen kann, indem man die Merkmale in der Formel anspricht oder diese einer Kennzahlen zuordnet, für die eine Ausnahmeaggregation hinterlegt ist, haben wir nicht versucht. Wie immer gibt es sicher noch viele weitere Möglichkeiten an das Ziel zu kommen.
Unabhängig von der hier vorgestellten Lösung, kann solch eine Fragestellung häufig auch in einer Query mit Formeln gelöst werden. Dies ist aber dann auf eine einzelne Query beschränkt und mit ähnlichen Einschränkungen behaftet.
Fazit
Auch wenn die Erklärungen und das Verhalten zuerst verwirrend klingt, folgt die Software wie immer einfachen Regeln ?. Hat man diese Verstanden, dann kann die neue Funktionalität ohne „böse“ Überraschung verwendet werden. Viel Spaß dabei!
Ansprechpartner

Dr. Ulrich Meseth
Senior Consultant

")



