Einführung
Machine Learning ist äußerst wichtig, wenn es darum geht, den vollen Nutzen aus Daten zu ziehen. Fortgeschrittene Machine Learning Algorithmen können dafür verwendet werden, eine große Vielfalt von Informationen aus Daten unterschiedlichster Quellen zu extrahieren. Allerdings ist der Prozess der Datenerfassung, -umwandlung und des Trainings von Modellen sehr aufwendig und langwierig. Dementsprechend ist es ein vollständiger Machine-Learning-Lebenszyklus ein beeindruckendes Konstrukt, insbesondere dann, wenn dafür eine einzige Plattform verwendet werden kann, die jeden Schritt dieses Lebenszyklus auf einmal abbilden kann. Bei dieser Plattform handelt es sich um Databricks.
Databricks ist eine Cloud-Umgebung in der Data Engineers (Dateningenieure), Data Scientists (Datenwissenschaftler) und Data Analysts (Datenanalysten) gemeinsam arbeiten können. Sie kann mit verschiedenen Cloud-Anbietern, wie Azure oder AWS verwendet werden. Die Data Engineers arbeiten hauptsächlich mit Spark, die Data Scientists mit MLFlow und Python und die Data Analysts mir SQL. Somit erschließt sich, dass die Mittel vorhanden sind, um ganze Lebenszyklen von Datenanalysen in Databricks abzubilden, allerdings kann es hierbei zu einer Schwierigkeit kommen. Die Rechenleistung wird in Databricks von sogenannten Clustern zur Verfügung gestellt. Diese Cluster benötigen etwa drei bis fünf Minuten, um zu starten und können bei einem dauerhaften Betrieb (24/7 hochgefahren) recht teuer werden. Das ist in den meisten Anwendungsfällen, in denen Daten in Schüben verarbeitet und ausgewertet werden, kein Problem. Allerdings können immer erreichbare Services auf diese Weise nur äußerst ineffizient zur Verfügung gestellt werden.
In diesem Blog-Beitrag wird ein Experiment dargestellt, in dem ein Machine-Learning-Projekt durchgeführt wird, das Databricks zur Durchführung und azureml zur Bereitstellung verwendet. Das Ziel des Projekts ist es, auf Basis von Daten eines Team-gegen-Team-Videospiels vorherzusagen, welches von zwei Teams in Runden dieses Videospiels gewinnen wird. In dem gewählten Videospiel spielen zwei Teams, bestehend aus je fünf Spielern, gegeneinander. Das Ziel ist es, die Basis des Gegners zu eliminieren, indem vorher eine Reihe andererZiele zerstört werden. Dabei verbessern sich die Charaktere der Spieler im Laufe des Spiels und kämpfen auch mit den Charakteren der Gegner. Für die Vorhersage darüber, welches Team eine Runde gewinnen wird, sollen nur die Daten der ersten zehn Minuten verwendet werden. Offensichtliche Maße dafür, wie gut ein Team gerade steht, sind beispielsweise die Stärke der individuellen Charaktere zu bestimmten Zeitpunkten oder wie viele gegnerische Ziele bereits ausgeschaltet wurden.
Das ausgewählte Fallbeispiel mag eventuell ungewöhnlich im Kontext der sonst von biX behandelten Themen erscheinen, allerdings werden die Themen von Fallbeispielen meist frei von den Zuständigen ausgewählt. In diesem Fall wurde ein Videospiel für das Experiment aus Gründen des generellen Interesses, Verfügbarkeit der Daten und Komplexität des Fallbeispiels ausgewählt.
Datenextraktion und -transformation
Die Daten für das Experiment werden aus einer API extrahiert. Die Extraktion ist in einem Databricks Notebook gecodet. Dabei wird maßgeblich die requests Bibliothek von Python verwendet. Nach der Extraktion werden die Daten, bei denen es direkt möglich ist, in Spark Dataframes umgewandelt, die restlichen Daten werden mithilfe der pandas.json_normalize Funktion und anderen manuelleren Wegen der Umwandelung in Tabellenform abgeflacht. Dieser Schritt ist nötig, da die Daten im JSON-Format extrahiert werden. Wenn alle Daten als Dataframe vorliegen, werden sie als Delta Table im Azure Blob Storage persistiert (df.write.format(‘delta’).write(<file path>)). Das ausgewählte Format der Delta Tables hat hierbei den Vorteil, dass sie wie Tabellen aus relationalen Datenbanken verwendet werden können (inklusive Data-Warehouse-Funktionen, wie Change Data Capturing) und das, obwohl sie in einem Cloud Blob Storage liegen.
Natürlich werden die Daten ausführlich untersucht, bevor irgendwelche Aggregationen durchgeführt werden: Welche Spannen decken die Werte verschiedener Spalten ab? Welche Datentypen haben die Spalten? Korrelieren die Spalten miteinander? Welche Spalten werden benötigt und welche sind obsolet? Diese Fragen können alle beantwortet werden, indem die Daten in ein Databricks Notebook importiert werden und dort eine investigative Datenanalyse mit Spark, herkömmlichen Python oder SQL initiiert wird. Hierfür ist die einfache aber auch sehr nützliche display() Funktion ein passendes Mittel zur Visualisierung.
Im Machine Learning können selten die frisch extrahierten Daten direkt verwendet werden. Meistens müssen sie zunächst analysiert, aggregiert und vorbereitet werden. In dem präsentierten Fallbeispiel wird maßgeblich Folgendes unternommen: Viele Spalten werden mit Aggregationen auf ein Maximum kombiniert und anderen Spalten wird wiederum ein Gewicht (ein Faktor) hinzugefügt, um ihren Einfluss auf das später trainierte Modell zu erhöhen. Ein konkretes Beispiel zu den Gewichten: Die Werte der Spielercharaktere sind in den ersten Minuten weniger ausschlaggebend für den späteren Verlauf des Spiels als die Werte, die zum Beispiel bei der zehn-Minuten-Marke bestehen. Demensprechend werden Werte größer gewichtet, je später sie erfasst werden. Alle angewandten Aggregationen sind unkompliziert mit der Spark Dataframe API umzusetzen.
Am Ende der Vorverarbeitung müssen die Daten gut zugänglich als Delta Table abgelegt werden. Zusätzlich werden die transformierten Daten allerdings auch in Databricks im Feature Store hinterlegt. Das hat Vorteile, da zum Beispiel aus Notebooks heraus auf hinterlegte Daten im Feature Store zugegriffen werden kann, womit Trainingsdatensätze für das Training eines Modells gebildet werden können. Die Daten im Feature Store enthalten eine versionierte Version des Codes, mit dem sie hergeleitet wurden, was eine Rückverfolgbarkeit für spätere Zeitpunkte garantiert. Außerdem müssen mit dem Feature Store keine aufwendigen Code-Abschnitte für den Import von Daten geschrieben werden, da diese einfach zugänglich und fertig verarbeitet vorliegen.
Machine Learning
Um mit dem Machine Learning anzufangen, wird zunächst die Beladung der transformierten Daten in ein neues Notebook vorgenommen. Wie bereits beschrieben, wird der Feature Store für diesen Schritt verwendet, damit die Beladung einfach replizierbar ist. Hierfür wird zunächst eine Instanz des feature_store erstellt. Danach wird mlflow autolog aktiviert, um die Parameter und Trainingsmetriken des später verwendeten Algorithmus zu erfassen. Daraufhin wird das mlflow Experiment gestartet, was bedeutet, dass die gesamte nachstehende Logik für das Machine Learning in der Experimente-Sektion von Databricks einsehbar und wiederverwendbar ist.
Innerhalb des Experiment-Verlaufs werden die definierte Beladung aus dem Feature Store ausgeführt, die frisch geladen Daten in Trainings- und Testdaten aufgeteilt, die Parameter für den Algorithmus festgelegt, das Modell trainiert und die Zuverlässigkeit des Modells ermittelt: Die Beladung aus dem Feature Store erfolgt über den create_training_set() Befehl. Danach wird die sklearn Funktion train_test_split() verwendet, um die Daten in einen Trainings- und Testanteil zu unterteilen. Die Parameter für den Algorithmus werden als nächstes definiert, in verschiedenen Durchläufen werden diese stetig verändert, um eine optimale Performance zu erreichen. Glücklicherweise werden sämtliche Parameter von mlflow erfasst, wodurch die Nachverfolgung der bestfunktionierenden Parameter später kein Problem mehr darstellt. Mit nur einer Zeile wird das Machine Learning Modell initialisiert und trainiert. Natürlich wird dieser Schritt in verschiedenen Durchläufen abgeändert, da Parameter und Art des Algorithmus angepasst werden. In diesem Fall werden Decision Trees, Random Forests und Support Vector Machines getestet. Am Ende des Experiments wird das neu trainierte Modell getestet. Die Testergebnisse werden erfasst und mit dem Befehl mlflow.log_metrics() gespeichert.

Der Screenshot zeigt die Metriken der Testläufe für den Random Forest, Decision Tree und Support Vector Machine in genannter Reihenfolge.
Obwohl viele Experimente durchgeführt werden, ist es dennoch sehr einfach, das beste Modell darunter auszuwählen, da in MLFlow Experimente nach unterschiedlichen Kriterien gefiltert und sortiert werden können. So kann in diesem Fall für die drei Arten der verwendeten Algorithmen zeitnah der jeweils beste Vertreter ausgesucht werden. Unter den drei Algorithmen hat der Random Forest am besten abgeschnitten (alle drei Arten liegen jedoch nahe beieinander), jedoch eignet sich der Decision Tree beispielsweise dennoch sehr gut dafür, zu visualisieren, wie wichtig unterschiedliche Kriterien in dem Datensatz für die Algorithmen sind. So zeigen genannte Visualisierungen, dass das Gold, welches durch das Ausschalten von feindlichen Charakteren und Zielen erhalten wird, ein sehr bedeutender Faktor ist. Je mehr Gold, desto besser. Auch der physische Schaden, der an Feinde verteilt wird, ist von großer Bedeutung. Das lässt sich daran ablesen, dass beide Faktoren vom Entscheidungsbaum am ehesten dafür verwendet werden, um Spiele in Sieg oder Niederlage einzuordnen. Dies klingt zunächst offensichtlich, wenn manmit solchen Spielen vertraut ist. Dies ist es jedoch nicht, wenn man bedenkt, dass es pro Spiel tausende Faktoren zu beachten gibt. Der Einfluss, oder zumindest die Korrelation der genannten Faktoren mit dem Sieg eines Teams, ist im Folgenden zu sehen:
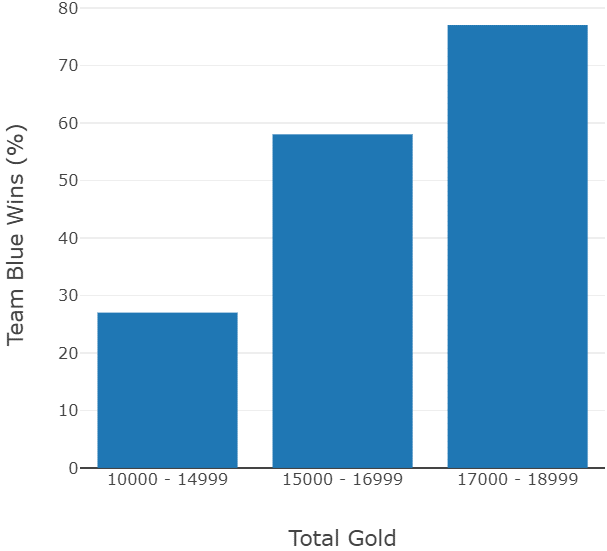
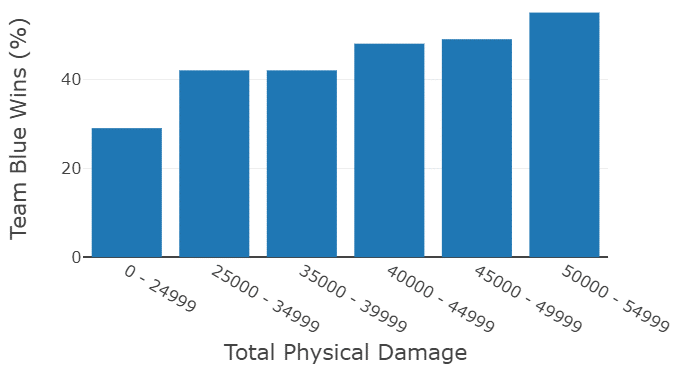
Die Wahrscheinlichkeit zu gewinnen steigt signifikantmit der Höhe der gezeigten Werte. Wie beschrieben, gibt es pro Partie eine große Zahl an spielbeeinflussenden Faktoren. Daher ist es umso überraschender, eine so deutliche Korrelation zwischen bestimmten Werten und der Siegeschance zu sehen.
Modellbereitstellung
Um das gerade erstellte Modell zugänglich zu machen, muss es ansprechbar gemacht werden. Natürlich wäre eine Methode, das Modell auf einem Databricks Cluster zur Verfügung zu stellen. Hierbei ergeben sich allerdings zwei Probleme: ein Databricks Cluster rund um die Uhr laufen zu lassen ist extrem teuer. Hinzu käme, dasswenn das Cluster flexibel starten soll, statt dauerhaft zu laufen, es etwa drei bis fünf Minuten benötigen würde. Diese Faktoren machen eine Bereitstellung über Databricks sehr ineffizient.
Um die genannten Probleme zu umgehen, wird das Modell stattdessen über azureml zu Verfügung gestellt. azureml ist ein Service, der über Azure verfügbar ist. Über diesen ist es möglich, das Modell permanent über einen Service bereitzustellen, ohne dafür viel zu bezahlen. Der Code zum Starten des Service kann allerdings problemlos in Databricks geschrieben werden. Als erstes werden alle notwendigen azureml Funktionen importiert:
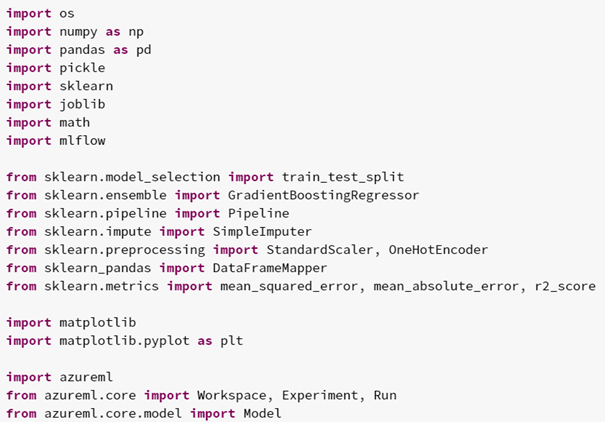
Im Anschluss wird der Workspace definiert, indem der Service laufen soll. Bei diesem werden Informationen mitgetragen, wie beispielsweise die Form des Azure Abonnements, in dem der Service laufen soll:
Daraufhin wird das Machine Learning Modell in azureml registriert:

Anschließend folgt ein sehr interessanter Part: Code-Teile für die Initialisierung und den Aufruf des Service können definiert werden. In diesen Code-Teilen kann beispielsweise angegeben werden, auf welche Weise die Eingangsdaten verarbeitet werden, bevor sie vom Modell zur Vorhersage benutzt werden. Durch diesen benutzerdefinierten Code wird der Service sehr flexibel, da er extrem anpassbar ist:
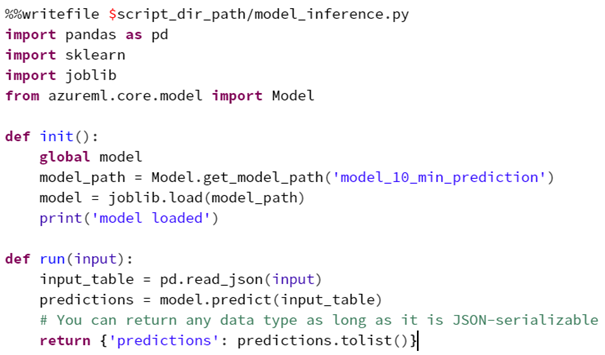
Folglich müssen die Bedingungen zum Starten des Service erfüllt werden. Die Umgebung, in der der Service läuft, wird definiert (welche Pakete und Funktionen werden benötigt):
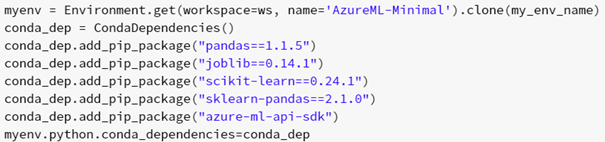
Die Konfiguration für die Vorhersage über das Modell wird angegeben (Pfad zum Code, frisch definierte Code-Teile und Workspace):
Die Konfiguration des Webservice wird erstellt (Anzahl der zu verwendenden CPU-Kerne, RAM):
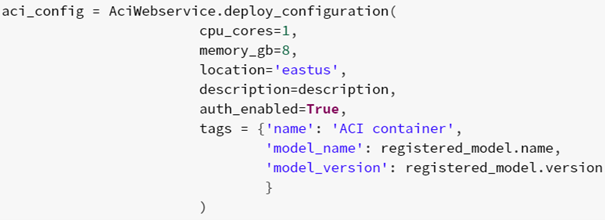
Zuletzt wird der Webservice erstellt (Name, Konfiguration, Informationen zum Modell):

Wenn alle Anforderungen definiert sind und der Webservice ausgeführt wird, kann ein API-Schlüssel generiert werden, um auf den Service zuzugreifen. Dann können neue, zu analysierende Daten, an den Service geschickt werden , sodass eine Antwort ausgegeben wird, welches Team siegen wird.
Zusammengefasst bietet Databricks viele komfortable Features für das Machine Learning. Mit dem Feature Strore und mlflow können Experimente versioniert, repliziert und kontrolliert eingesetzt werden. Die Bereitstellung kann problemlos aus Databricks heraus mit azureml durchgeführt werden. Hierbei sorgt der flexible Code für reichlich Freiraum bei der Implementierung. Dazu kommt, dass Machine Learning, Data Engineering und Data Analysis gemeinsam in Databricks durchgeführt werden können, wodurch es Teams ermöglicht wird, schnittstellenfrei miteinander zu arbeiten.
Jetzt bleiben endlich weder die Siege unserer Lieblingsteams, noch die Effizienz unserer Machine Learning Services dem Zufall überlassen.
Sollten Sie Fragen zum Machine Learning oder Databricks-Funktionen, wie dem Feature Store, haben, können Sie sich jederzeit gerne bei uns melden. Wir freuen uns auf Sie.
Ansprechpartner


")



