Customer-Churn ist die vom Kunden ausgehende Kündigung. Die Vorhersage solcher Ereignisse vor dem Eintreten ist in vielen Geschäftsbereichen von großem Interesse. Die Fokussierung von Gegenmaßnahmen auf relevante Kunden verringert den Aufwand und verhindert einen Schläfereffekt bei nicht gefährdeten Kunden.
Ein möglicher Weg zur Vorhersage von Churn soll hier mittels Decision Trees aus der SAP HANA Predictive Analysis Library (PAL) gezeigt werden. Als Datengrundlage dient ein Datenset von Kundendaten eines Telekommunikations- unternehmens mit bekannten Churn-Ereignissen.
Der Schläfereffekt beschreibt, dass Kunden erst durch den hergestellten Kontakt ihre Vertragsbedingungen bewerten und daraufhin kündigen.
Ein Decision Tree trennt den Datensatz möglichst genau in Churn-Kunden und Nicht-Churn-Kunden. Dafür erstellt er Entscheidungsregeln, für die er Kundenmerkmale verwendet, wie z.B. „Monatlicher Umsatz > X“ oder „Nutzung von Streamingangeboten Ja/Nein“. Die Kombination der Einzelregeln erlaubt dem Decision Tree dann schließlich die Zuordnung eines Kunden zu Churn/ Nicht-Churn.

Abbildung 1: Ausschnitt aus möglichem Decision Tree
Die Auswahl der Parameter bei der Erstellung eines Decision Trees beeinflusst sowohl die Genauigkeit der Zuordnung als auch die Komplexität der Regeln. Setzt man den Wert der Einfachheit hoch, so werden die Regeln weniger spezifisch, aber die Genauigkeit der Klassifizierung nimmt meist ab. Es gilt also zwischen Lesbarkeit und besserer Trennung abzuwägen.
Einfachheit beschreibt hier die nötige Zahl der Kunden, die mit einer Regel beschrieben werden. Wird dieser Wert nicht erreicht, so wird die Regel nicht gebildet und die weitere Aufteilung endet in diesem Zweig.
Für die Erstellung des Decision Trees und die Überprüfung der erstellten Regeln werden Trainings- und Testdatensets benötigt. In diesem Beispiel liegt der Datensatz in einem aDSO im SAP BW vor. Trainingsset und Testset werden für die Vergleichbarkeit von Durchläufen aus dem Datensatz als Tabellen persistiert. Die Datenvorverarbeitung und die Aufteilung der Daten erfolgten mittels ABAP.
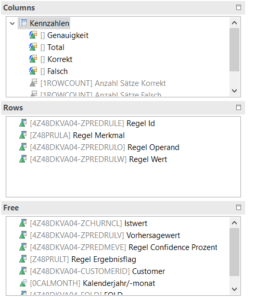
Nach der Erstellung der getrennten Sets wird die Qualität der erstellten Decision Trees zunächst mit dem Trainings- dann mit dem Testset beurteilt. Bei zufriedenstellender Genauigkeit der Trennung von Churn und Nicht-Churn wird ein finaler Decision Tree auf gemeinsamer Basis von Trainings- und Testdaten erstellt. Die Decision Trees werden mit einem Aufruf der SAP HANA PAL in ABAP erstellt. Die erstellten und kombinierten Regeln aus der PAL sind ohne weitere Formatierung nur schwer lesbar und noch nicht einzelnen Kunden zugeordnet. Für die Überprüfung der richtigen Anwendung der Stamm- und Bewegungsdaten in den Regeln ist ein Einblick aber wünschenswert. Zudem kann die Betrachtung, welche Regel für einen Kunden gilt, Hinweise darauf geben, welche Aspekte das Churn-Ereignis abwenden können. Daher werden die Regeln in weiteren ABAP-Programmen formatiert und jedem Kunden die angewendete Regel zugeordnet. Die aufbereiteten Regeln werden mit den Kundendaten in einem aDSO zusammengeführt und können per Query ausgewertet werden.
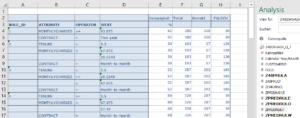
Mit einer Einfachheit von 150 wird eine Genauigkeit von über 75% über den gesamten Datensatz erreicht. Die Betrachtung auf Regelebene erlaubt aber auch die Bewertung der Genauigkeit der einzelnen Regeln, die auch mehr als 90% erreichen kann.
So können die Maßnahmen für die Churn-Prevention auf gefährdete Kunden mit ausreichender Vorhersagegenauigkeit fokussiert werden. Dadurch können Kosten für Vertriebsmaßnahmen verringert und die Effizienz durch die Vermeidung falscher Kundenkontakte erhöht werden.
Ansprechpartner


")



