Entscheidungshilfe, wann welche Lösung genutzt werden soll
Die SAP Analytics Cloud (SAC) ist das strategische Datenanalysestool der SAP, welches Business Intelligence-, Dashboarding-, Visualization-, Planning- und Predictive Funktionalitäten in einer Lösung vereint. Um die Daten auszuwerten oder zu planen bietet SAP nun zwei Ansätze – die Story oder die Analytic Application.
Einführung
Durch den Self-Service Ansatz unter Data Discovery (Vorschlagen von Storys) wird es ermöglicht, Fachabteilungen selbst in den Daten-Visualisierungsprozess einzubinden. Durch künstliche Intelligenz und Machine Learning schlägt die SAC schon heute Storys vor, die ohne vielen weiteren Aufwand, brauchbare Insights liefern. Jedoch gibt es noch eine andere Art, wie Daten visualisiert werden können, und zwar mit Analytic Applications. Diese sollen laut der SAP deutlich flexibler als Storys sein und können somit Kundenwünschen besser entsprechen. Diese Flexibilität wird in dem Application Designer, der deutlich von der Arbeitsumgebung von Stories abweicht, durch Scripting ermöglicht. Dies wird durch einen höheren Erstellungsaufwand erkauft.
In diesem Blogeintrag wird der Unterschied von Storys zu Analytic Applications aufgezeigt. Wann es womöglich Sinn ergibt, eine Story zu verwenden oder eben eine Analytic Application. Des Weiteren geht es um die Frage, ob die Fachabteilung Analytic Applications ohne Unterstützung durch die IT gewinnbringend nutzen und aufbauen kann. Es gibt zwar schon einen Blog, der die Vorteile von einer Analytic Application aufzeigt, jedoch noch keinen direkten Vergleich im deutschsprachigen Raum (Link siehe unten).
Allgemein
Sowohl Storys als auch Analytic Application dienen dazu, die aufbereiteten Daten verständlich zu präsentieren und visualisieren. Denn erst durch eine zielgruppendefinierte, klare und verständliche Datenvisualisierung kann das volle Potenzial der Daten ausgeschöpft werden. Hierbei können Tabellen, Graphen, Diagramme und weitere Visualisierungselemente zum Einsatz kommen. Mit Hilfe dieser Elemente wird ein tiefer Einblick in das Business und die Organisation ermöglicht.
Story
Die Story zeichnet sich durch ein klares und einfaches Konzept aus, welches ohne großen Aufwand eingerichtet werden kann. Die Visualisierung von einfachen Szenarien und Fragestellung stehen im Vordergrund, genauso wie die losgelöste Planung. Bei komplexeren Fragestellungen oder einem umfassenden integrierten Planungsprozess stößt die Story schnell an ihre Grenzen.
Die Erstellung und Bearbeitung von Stories kann schnell erlernt werden, weswegen Sie ideal für den Self-Services ist und nicht ein umfassendes Knowhow voraussetzt. Dies wird durch eine dialog-geführte Bedingung verstärkt, welche sowohl vom Ersteller als auch vom Nutzer leicht zu bedienen ist.
Bei der Erstellung einer Story muss nur einmalig entschieden werden, welches Grundlayout gewählt werden soll. Nach der Entscheidung, beispielsweise eines responsiven Layouts, braucht es kein Gedanke an die Skalierbarkeit der Story auf mobilen Endgeräten wie Tablets oder Handy verschwendet werden. Dies wird automatisch gewährleistet.
Analytic Application
Analytic Application sind dazu geeignet komplexe Anforderungen abzubilden. Diese Anforderungen können sich durch Szenario, Fragestellung, Funktionalitäten, Darstellungen und/oder Nutzerführung ausdrücken. Auf Grund vielfältiger Ziele sollte ein Konzept erstellt werden, wobei die Erwartungen und Funktionalitäten klar herausgearbeitet werden sollten. Denn durch personalisierte Benutzerführungen, Skripting Logiken, Drill-Downs kann schnell ohne ein vernünftiges Konzept, die Übersichtlichkeit verloren gehen. Mit einem ausgefeilten Konzept können komplexe Zusammenhänge im Reporting oder in einer umfassenden Planung umgesetzt und Nutzerführung deutlich personalisierter werden.
Die Erstellung ist deutlich aufwendiger und setzt mehr technisches Knowhow und Grundverständnis voraus, da die grafischen Elemente sich mit Hilfe von Scripting beeinflussen und verändern lassen. Um eine reibungslose Nutzung der Analytic Application zu gewährleisten, muss somit Scripting betrieben werden. Zusätzliche Funktionen sind neben der Veränderung von fast jedem visuellen Element, das Arbeiten mit Buttons, Pop Ups, Scripting und dem Odata Services. Wer Lumira kennt, wird sich hier schneller zurechtfinden und wissen, wo die Fallstricke lauern, aber auch, welches Potenzial möglich ist. Außerdem ist der Aspekt der Wartbarkeit zu beachten, da Anpassungen ebenfalls höheren Aufwand darstellen als bei Stories.
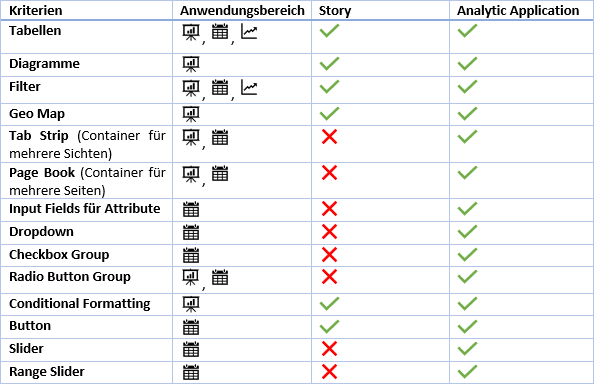
Funktionsvergleich
In der folgenden Tabelle wird ein Überblick über die wichtigsten Features geben und wo diese verfügbar sind. Diese Liste erhebt keinen Anspruch auf Vollständigkeit und will auch nicht die Details beschreiben, da der Blog nur eine Entscheidungshilfe ist und nicht tiefgehend die technischen Unterschiede analysiert.

Data Action Trigger unterscheiden sich in der Verwendung. In der Story kann eine Data Action nur über den Standardbutton getriggert werden. In der Analytic Application kann sie über diverse andere Userinteraktionen ausgelöst werden. Den Data Analyzer kann nicht aus einer Story heraus aufgerufen werden. Ohne das Erstellen einer Story kann er über einen angepassten URL aufgerufen werden. In einer Analytic Application ist es jedoch mit einem Befehl ohne Probleme möglich.
Fazit
Ich empfehle nicht als Erstes zu überprüfen, ob eine Analytic Application Sinn ergibt, sondern ob es möglich ist, seine Anforderungen mit einer Story umzusetzen. Dadurch können Aufwände eingespart werden und man kommt nicht in Versuchungen seine Anforderungen komplexer zu machen, als sie eigentlich sind. Erst wenn es nicht möglich ist, seine Anforderungen umzusetzen, sollte man sich der Analytic Application zuwenden.
Wenn mit Analytic Applications gearbeitet wird, ist es wichtig, dass klare Anforderungen und Erwartungen kommuniziert und diese festgelegt und nicht des Öfteren Anpassungen vorgenommen werden. Dies ist einer der häufigsten Gründe, warum Projekte in dem Bereich aus dem Budget laufen.
Des Weiteren kann festgehalten werden, dass für die Analytic Application schon eine gewisse IT-Affinität vorausgesetzt wird und das eine Fachabteilung, die keine Programmier- oder Scriptingkenntnisse hat, hier nicht so schnell weiterkommen wird.
Zusammenfassung der verschiedenen Kriterien:

Weiterführende Links:
- Vorteile einer Anayltic Application über eine Story
https://blogs.sap.com/2020/08/13/advantages-of-an-analytic-application-over-story-in-sap-analytics-cloud-part-1/ - Wann sollte in der Planung auf Analytic Applications zurückgegriffen werden
https://blogs.sap.com/2021/03/17/analytics-designer-for-the-planning-process-when-is-the-right-time/ - Business Cases, wann der Analytics Designer helfen kann
https://blogs.sap.com/2020/10/12/analytics-designer-five-business-cases-for-truly-informed-experiences/
Ansprechpartner


")



